PRO site has been launched!
Posted by sevagh on 17 February 2024
Category: announcements
Last updated: 2024-09-20
Table of contents
- Announcing our new PRO site!
- AI demixing competitions
- Latest research
- Our PRO models
- 🔥🔥 World-class drums and bass stems??
- Stay up to date!
Creating ensemble models for better demixing 📈
Announcing our new PRO site!
Over the course of the last month, we have been hard at work on this project, and we’re ready to show you what we came up with!
Browse and sign up for our PRO website today!
AI demixing competitions
The Sound Demixing Challenge 2023, recently wrapped up. It’s a continuation of the first Music Demixing Challenge 2021. These research challenges are hugely important in the field of music demixing. The first hybrid time-frequency Demucs model (v3) was created during MDX 2021.
When the best music demixing and source separation researchers and engineers are in one place and pushing themselves to improve and win cash prizes, the field advances.
Latest research
The winning teams in the SDX 2023, creators of the MVSep website, published their paper on their winning SDX 2023 strategies:
- They use ensemble models to combine Demucs and other AI models: that is to say, they run many different AI models and average or combine their outputs to create 1 set of stems for 1 input song
- They use test-time augmentation, or inference augmentation, in the form of inverted waveforms
That means that you apply the demixing model to the original song and to the inverted song (waveform * -1.0), re-invert the inverted stems output, and now you have two independent and slightly different sets of separated stems for the same song.
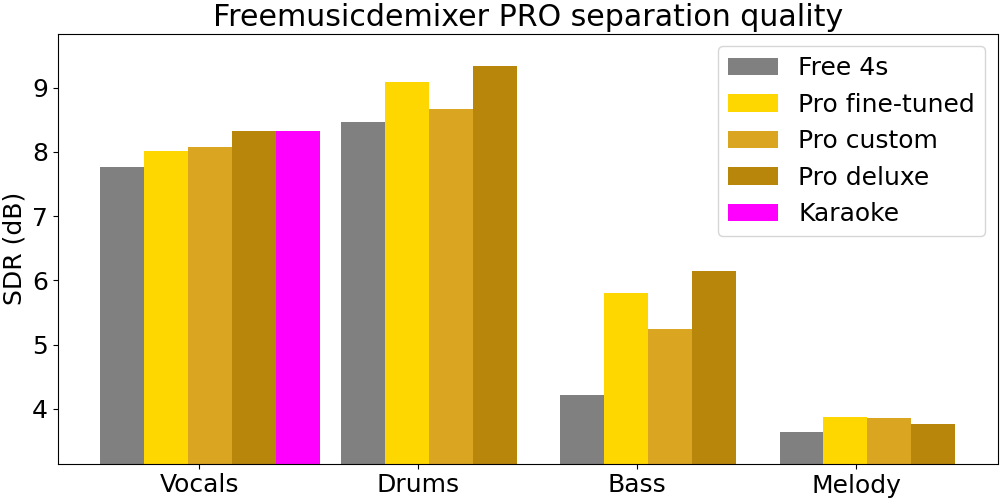
Our PRO models
As part of the new pro release, we are launching with 4 models:
- Karaoke/vocal-only: we apply a custom Demucs fine-tuned vocal model with test-time inverted waveform augmentation for an exclusive improved vocal separation at 2x inference cost (the AI is run twice on the input song) for maximum vocal quality, beating Demucs v4 fine-tuned vocals
- Pro fine-tuned model: this is the original Demucs v4 Fine-tuned model, which has a 4x inference cost and has particularly good drum, bass, and melody performance
- Pro custom model: we start with the Karaoke model, and then follow up with running Demucs 4-source and 6-source twice each on the instrumental output; the end result is 6x inference cost for a well-rounded model that outputs the the most stems, including improved vocals, drums, bass, guitar, piano, melody, and other
- Pro deluxe model: this combines the best of our Karaoke model and test-time inverted waveform augmentation at 8x inference cost for world-beating drums and bass separation
🔥🔥 World-class drums and bass stems??
I really believe it. I have added audio clips to demo the Pro Deluxe model, and I’m confident that drum and bass stems extracted by my Pro Deluxe model are world-class. Try it for yourself! The results are astonishing.
Stay up to date!
Remember to use the promo code LAUNCH10, which is valid until March 31 2024, to test-drive the new ensemble models.
Stay tuned for further updates and upcoming models! This is just the beginning.