


Multi-threading Demucs: overlap-adding on two levels
Posted by sevagh on 23 February 2024
Category: under-the-hood
Table of contents
- Demucs segmented inference
- Boundary artifacts and the overlap-add method
- Single-threaded Demucs in the browser
- Threading the C++/WASM module? Not so easy
- Threading on the Javascript level? Now we’re talking
How we use Demucs to process overlapping segments in two places (Javascript and C++) for multi-threaded demixing in the browser
Demucs segmented inference
Demucs, the PyTorch project, has a file apply.py which implements splitting of a waveform into segments:
out = th.zeros(batch, len(model.sources), channels, length, device=mix.device)
sum_weight = th.zeros(length, device=mix.device)
segment_length: int = int(model.samplerate * segment)
stride = int((1 - overlap) * segment_length)
offsets = range(0, length, stride)
# We start from a triangle shaped weight, with maximal weight in the middle
# of the segment. Then we normalize and take to the power `transition_power`.
# Large values of transition power will lead to sharper transitions.
weight = th.cat([th.arange(1, segment_length // 2 + 1, device=device),
th.arange(segment_length - segment_length // 2, 0, -1, device=device)])
assert len(weight) == segment_length
# If the overlap < 50%, this will translate to linear transition when
# transition_power is 1.
weight = (weight / weight.max())**transition_power
for offset in offsets:
chunk = TensorChunk(mix, offset, segment_length)
chunk_out = apply_model(model, chunk, **kwargs)
offset += segment_length
chunk_length = chunk_out.shape[-1]
out[..., offset:offset + segment_length] += (
weight[:chunk_length] * chunk_out).to(mix.device)
sum_weight[offset:offset + segment_length] += weight[:chunk_length].to(mix.device)
out /= sum_weight
return out
The segment size is 7.8 seconds for the Demucs v4 hybrid transformer model, and in the code, it looks like a weighted triangular window is being applied to the transition. This detail is important later.
It makes sense to split the workload in case running the Demucs model inference on the entire song all at once is not computationally feasible. However, there is a 0.25 second overlap between the split segments, and a weighted linear transition between adjacent segments when copying each segment into the final output waveform, since two segments are contributing to the overlapping section. Here is an illustration:
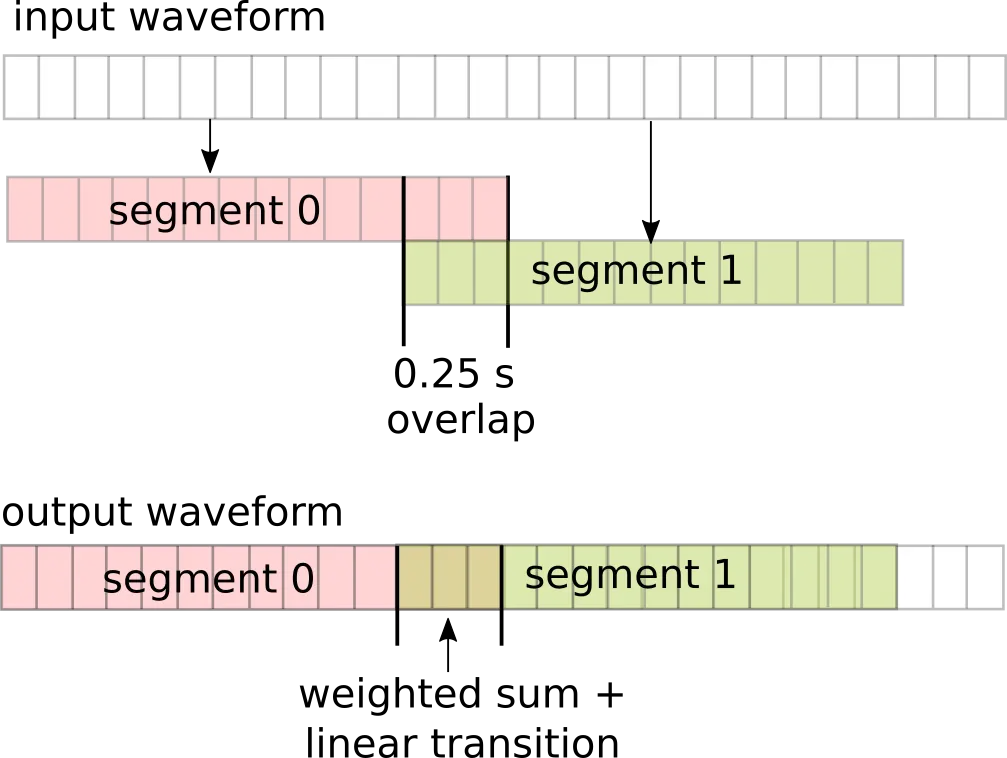
Why go through all this trouble? Two words: boundary artifacts.
Boundary artifacts and the overlap-add method
When we demix a 7.8-second segment independently, we get some output waveforms for the 4 stems. Each independent execution of Demucs inference is influenced by all of the consecutive samples in the specific waveform:
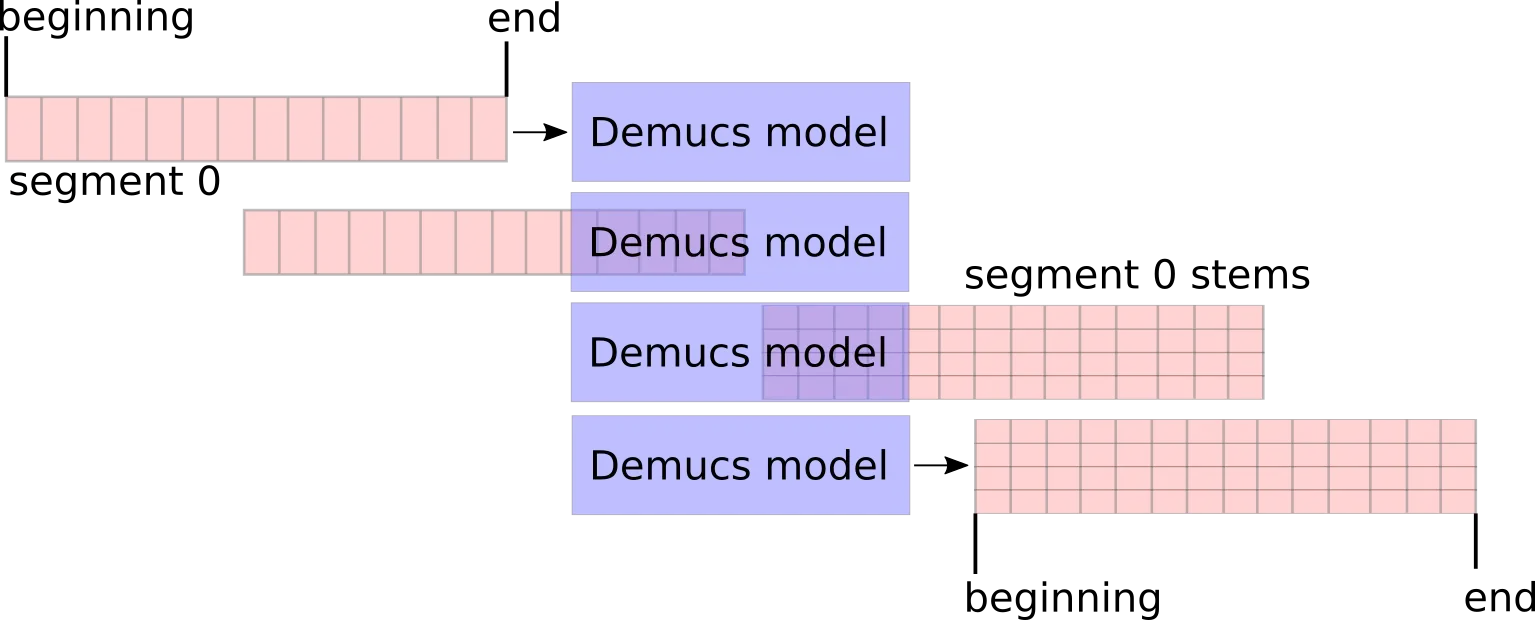
Illustration of a naive case where we take non-overlapping segments:
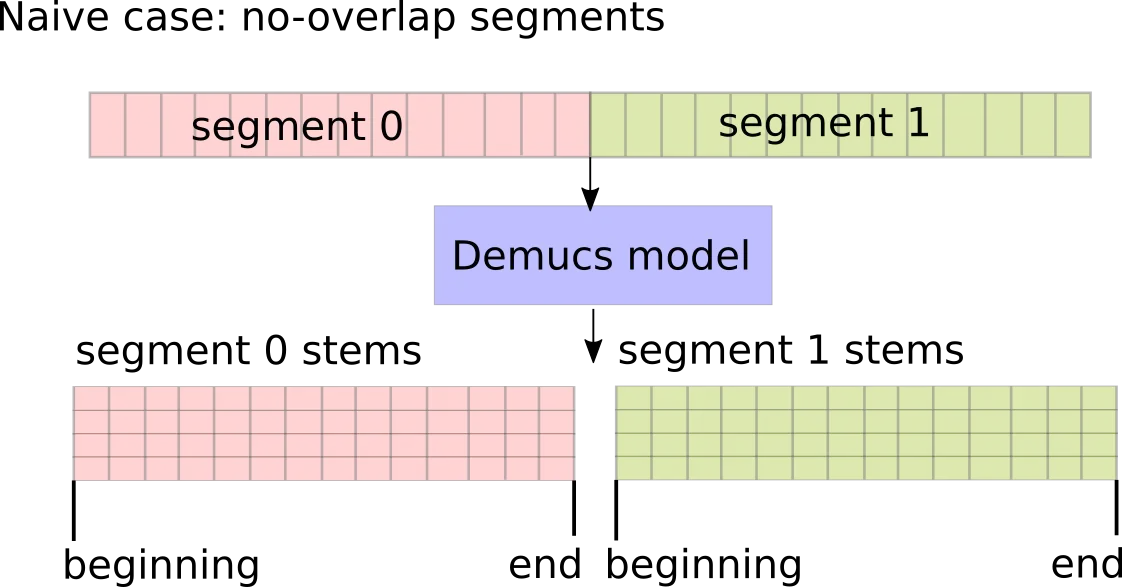
What happens in this case? We will hear audible clicks or discontinuities at the joining sample. Simply put, because Demucs demixed each segment independently, the end of segment 0 stems have absolutely no relationship with the beginning of segment 1 stems. Even though they were neighbors in the input waveform, after being processed by Demucs, the output stems can no longer be slapped together as neighbors.
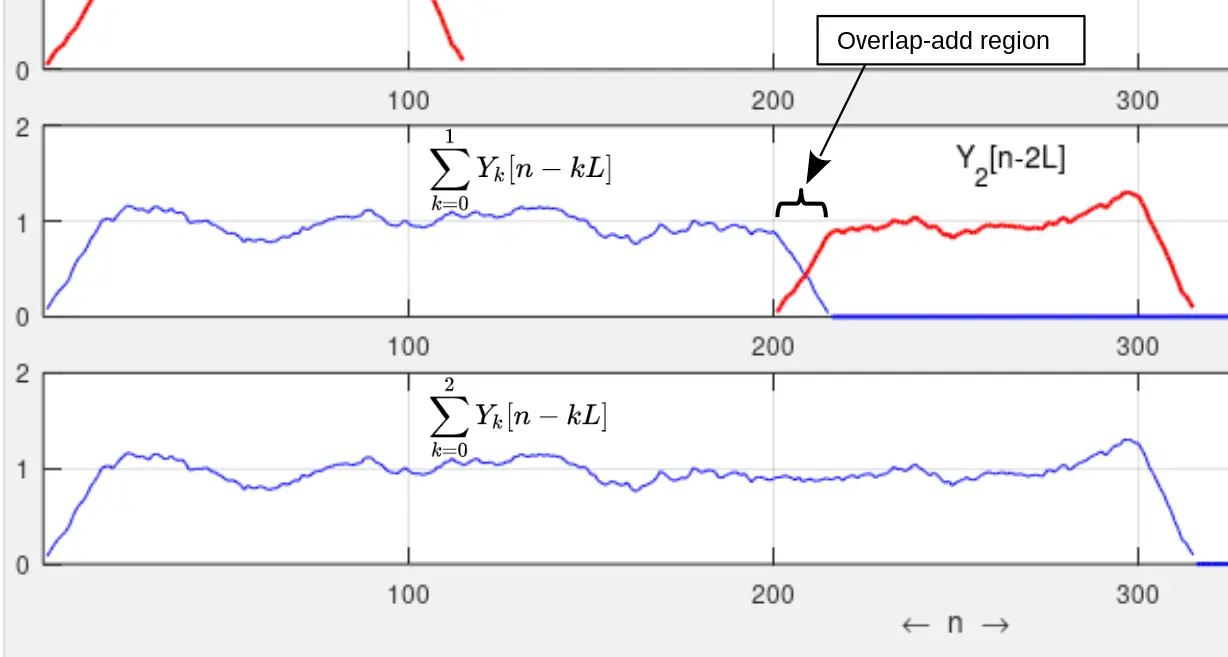
That’s why it’s important to have an overlap with a weighted overlap transition in between. The contributions of the “alien” neighboring samples of the end of segment 0 and the beginning of segment 1 are summed together and normalized so that instead of hearing a click, they elegantly blend together. The Wikipedia article on the overlap-add method contains a diagram showing this smoothing/blending effect:
In the Stanford CCRMA page on the Weighted Overlap Add, Julius Smith describes the procedure:
In the weighted overlap add (WOLA) method, we apply a second window … prior to the final overlap-add to create the output signal. Such a window can be called a “synthesis window” … or simply “output window.” Output windows are important in audio compression applications for minimizing “blocking effects.” The synthesis window “fades out” any spectral coding error at the frame boundaries, thereby suppressing audible discontinuities. The WOLA method is most useful for nonlinear “instantaneous” FFT processors such as perceptual audio coders, time-scale modification, or pitch-shifters. In these and other nonlinear signal processing operations, the output window helps to suppress artifacts caused by nonlinear spectral modifications.
I highlighted the “nonlinear signal processing operations” phrase to guess that Demucs can be considered a form of (very complicated) nonlinear signal processing operation, since it consists of building blocks like the STFT, convolution, and various neural network operations like activation functions (GELU, GLU), self-attention, etc.
I asked ChatGPT to help summarize these ideas:
The weighted-overlap-add method is crucial for applying Finite Impulse Response (FIR) filters to segmented sections of long audio waveforms, effectively mitigating boundary effects and ensuring seamless transitions. Demucs, embodying a highly complex FIR filter through its convolutional layers and neural network architecture, leverages this principle to tackle similar challenges in audio processing. By adopting weighted-overlap-add techniques, Demucs efficiently addresses boundary issues inherent in segment-based processing, ensuring high-quality audio source separation with minimal artifacts.
I then asked it to convince me that Demucs can be considered as one big fat “FIR filter”:
The convolution operation, a cornerstone of signal processing and central to the operation of FIR filters and neural networks like Demucs, can be viewed through the lens of linear time-invariant (LTI) systems. This perspective is grounded in the filtering approach where the output of an LTI system, or in this case, a neural network, is the convolution of the input signal with the system’s impulse response. Thus, Demucs and similar neural networks can be conceptualized as complex, adaptive FIR filters, applying learned transformations to audio signals to achieve specific processing goals, such as audio equalization or source separation.
Finally, it went further to explain the role of deep learning in learning audio filters:
Research in designing audio equalization filters using deep neural networks underscores the adaptability and efficacy of neural networks in audio processing tasks. By tuning filter coefficients through deep learning, significantly improved outcomes in audio quality can be achieved, underscoring the potential of neural networks to act as sophisticated FIR filters for complex audio equalization challenges.
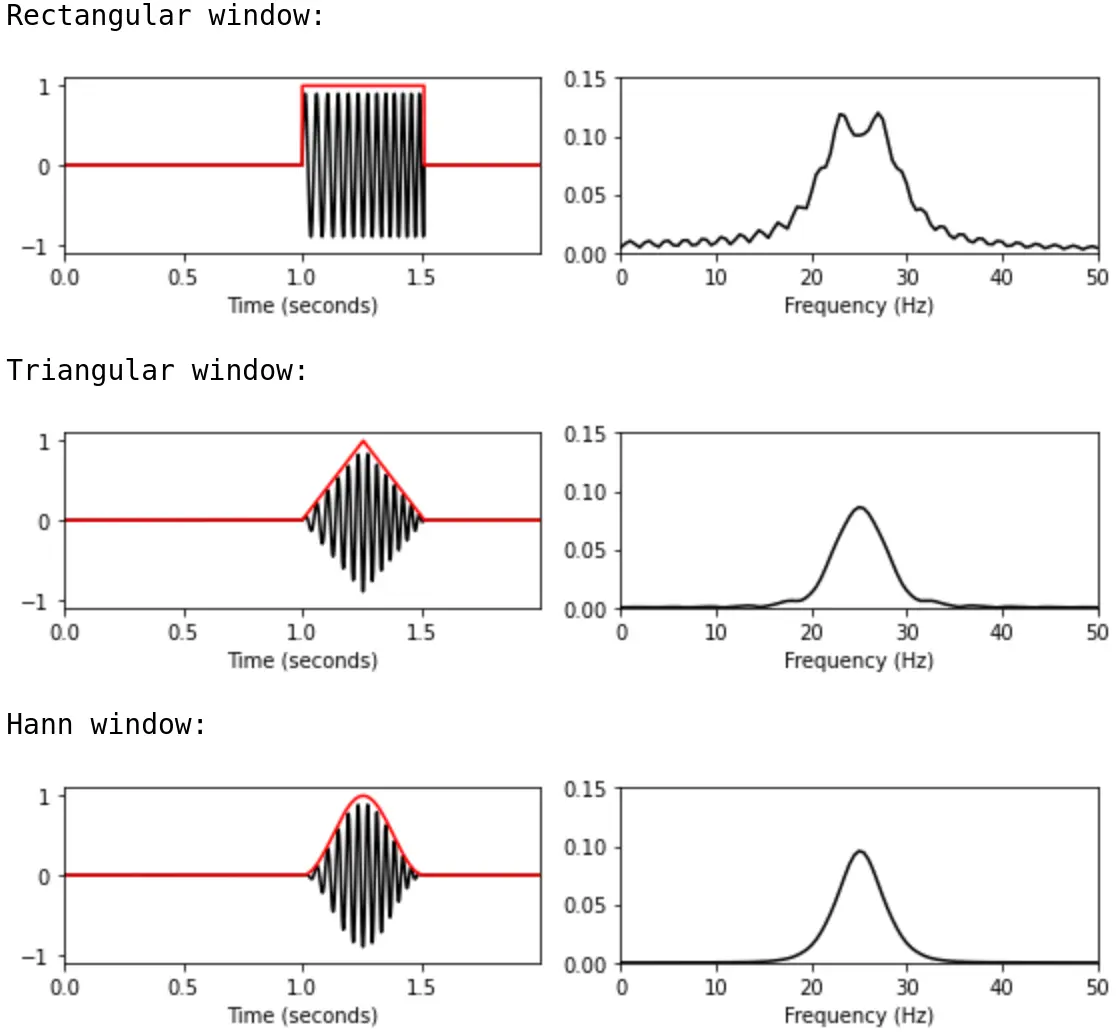
Triangular window function
We can think of the no-transition case as a rectangular window. Segment 0 abruptly stops outside of the segment-sized rectangle, while Segment 1 abruptly begins. In this diagram from Audiolabs Erlangen, we can see the improved effect of the triangular window on boundary discontinuities compared to the rectangular case by examining the frequency response of the window function:
Single-threaded Demucs in the browser
In the original, single-threaded version of the AI model on this site, the design was as follows:
- User inputs an audio file
- Javascript loads the audio file to get an audio waveform (left channel, right channel, length, sample rate)
- Javascript passes the waveform data to the C++ Demucs module (compiled to WebAssembly)
- The Demucs C++ code faithfully applies the same model apply as the original PyTorch version of Demucs: that is to say, it splits the waveform into overlapping segments (7.8-seconds long), demixes them consecutively, and recombines them with a weighted overlap-add with the triangle window
The downsides are:
- There is an upper limit to the track size. Each WASM module is constrained to consuming only 4 GB of memory, so a larger song (like a 15-minute Meshuggah song) would spill over this limit with all the space it takes up to construct the huge output waveform, etc.
- The total processing is slow, since for a given song that has M segments, we need to wait for M segment inferences done consecutively on a single thread, using only one core of your computer
- Why use one core or only 4 GB of memory when most typical devices have many more than that?
Threading the C++/WASM module? Not so easy
Given that the Demucs C++ inference splits the input waveform into 7.8-second segments, implementing multi-threading seems easy on the surface:
- Load the Demucs model
- Split the waveform into overlapping segments
- Launch N threads to process N segments at a time
- Sum the N output segments into the output waveform with the triangle window overlap
- Repeat until finished
- Return the output waveform
The issue with this is I would need some shared memory between the outer controller (with the Demucs model, input waveform, output waveform, and triangular window) and the inner threads (running the model per-segment). I didn’t want to redesign my C++ code to support a SharedArrayBuffer, and the WebAssembly threading kind of makes no sense to me: all I wanted was, in my inner code, something like:
... rest of C++ code...
struct demucs_model model = load_model(model_data);
std::vector<Eigen::MatrixXf> split_waveform = split_waveform(input_audio);
int n_threads = 4;
// launch 4 threads to process 4 waveforms of split_waveform at a time
for (int processed_waveforms = 0; processed_waveforms < split_waveform.size(); processed_waveforms += n_threads) {
process_in_parallel(model, split_waveform[:processed_waveforms]);
}
Nothing in the WASM threading or shared memory toolbox was making sense.
Threading on the Javascript level? Now we’re talking
What I actually ended up doing was kind of cool. Recall that Demucs is very amenable to independent parallel processing: there is no notion of temporal sequence. Any part of the waveform can in essence be demixed independently of the others. This is in stark contrast to recurrent neural network designs (like the LSTM, Long Short-Term Memory) architecture of Open-Unmix, where demixing a part of the waveform requires knowledge of all the previous and future samples.
The trick here is that, by doing any segmented audio processing, just like the 7.8-second segments of the Demucs inference, we need to be careful about segment boundaries and apply similar triangle window overlap-adding to avoid segmentation or audible clicks or discontinuities.
That’s the magic of the way we do multi-threaded Demucs:
- In Javascript, split the waveform into N large overlapping segments (larger than 7.8 seconds)
- Launch a separate Demucs C++ WASM module for each N large overlapping segment for N total threads of Demucs
- Within the Demucs WASM module, the large overlapping segment is split into our familiar consecutive small overlapping segments of 7.8-seconds long per-thread with the inner form of the triangle overlap-add summation
- Recall that each of these module instances has a 4 GB limit, so the total memory limit is 4 x N GB; that’s why to change the number of workers on the main site, you set your total number of memory (up to 32 GB or 8 workers)
- This lets us handle much larger total song sizes as well
- Recombine the N large overlapping segments output with the outer form of the triangle overlap-add summation
This is a rough sketch of what the Javascript code looks like.
Split into large segments:
const SAMPLE_RATE = 44100;
const OVERLAP_S = 0.75;
const OVERLAP_SAMPLES = Math.floor(SAMPLE_RATE * OVERLAP_S);
function segmentWaveform(left, right, n_segments) {
const totalLength = left.length;
const segmentLength = Math.ceil(totalLength / n_segments);
const segments = [];
for (let i = 0; i < n_segments; i++) {
const start = i * segmentLength;
const end = Math.min(totalLength, start + segmentLength);
const leftSegment = new Float32Array(end - start + 2 * OVERLAP_SAMPLES);
const rightSegment = new Float32Array(end - start + 2 * OVERLAP_SAMPLES);
// Overlap-padding for the left and right channels
// For the first segment, no padding at the start
if (i === 0) {
leftSegment.fill(left[0], 0, OVERLAP_SAMPLES);
rightSegment.fill(right[0], 0, OVERLAP_SAMPLES);
} else {
leftSegment.set(left.slice(start - OVERLAP_SAMPLES, start), 0);
rightSegment.set(right.slice(start - OVERLAP_SAMPLES, start), 0);
}
// For the last segment, no padding at the end
if (i === n_segments - 1) {
const remainingSamples = totalLength - end;
leftSegment.set(left.slice(end, end + Math.min(OVERLAP_SAMPLES, remainingSamples)), end - start + OVERLAP_SAMPLES);
rightSegment.set(right.slice(end, end + Math.min(OVERLAP_SAMPLES, remainingSamples)), end - start + OVERLAP_SAMPLES);
} else {
leftSegment.set(left.slice(end, end + OVERLAP_SAMPLES), end - start + OVERLAP_SAMPLES);
rightSegment.set(right.slice(end, end + OVERLAP_SAMPLES), end - start + OVERLAP_SAMPLES);
}
// Assign the original segment data
leftSegment.set(left.slice(start, end), OVERLAP_SAMPLES);
rightSegment.set(right.slice(start, end), OVERLAP_SAMPLES);
segments.push([leftSegment, rightSegment]);
}
return segments;
}
Summing the segments:
function sumSegments(segments, desiredLength) {
writeJsLog("Summing segments")
const totalLength = desiredLength;
const segmentLengthWithPadding = segments[0][0].length;
const actualSegmentLength = segmentLengthWithPadding - 2 * OVERLAP_SAMPLES;
const output = new Array(segments[0].length).fill().map(() => new Float32Array(totalLength));
// Create weights for the segment
const weight = new Float32Array(actualSegmentLength);
for (let i = 0; i < actualSegmentLength; i++) {
weight[i] = (i + 1);
weight[actualSegmentLength - 1 - i] = (i + 1);
}
// normalize by its max coefficient
const maxWeight = weight.reduce((max, x) => Math.max(max, x), -Infinity);
const ramp = weight.map(x => x / maxWeight);
const sumWeight = new Float32Array(totalLength).fill(0);
segments.forEach((segment, index) => {
const start = index * actualSegmentLength;
for (let target = 0; target < segment.length; target++) {
const channelSegment = segment[target];
for (let i = 0; i < channelSegment.length; i++) {
const segmentPos = i - OVERLAP_SAMPLES;
const outputIndex = start + segmentPos;
if (outputIndex >= 0 && outputIndex < totalLength) {
output[target][outputIndex] += ramp[i % actualSegmentLength] * channelSegment[i];
// accumulate weight n_targets times
sumWeight[outputIndex] += ramp[i % actualSegmentLength];
}
}
}
});
writeJsLog("Normalizing output")
// Normalize the output by the sum of weights
for (let target = 0; target < output.length; target++) {
for (let i = 0; i < totalLength; i++) {
if (sumWeight[i] !== 0) {
// divide by sum of weights with 1/n_targets adjustment
output[target][i] /= (sumWeight[i]/(output.length));
}
}
}
return output;
}
Launching independent Demucs workers per large segment:
// Function to handle the segmented audio processing
function processAudioSegments(leftChannel, rightChannel, numSegments, originalLength) {
let segments = segmentWaveform(leftChannel, rightChannel, numSegments);
segments.forEach((segment, index) => {
workers[index].postMessage({
msg: 'PROCESS_AUDIO',
leftChannel: segment[0],
rightChannel: segment[1],
originalLength: originalLength
});
});
}
Recombining independent Demucs outputs per large segment:
// Handle the processed segment
// Collect and stitch segments
processedSegments[i] = e.data.waveforms;
let originalLength = e.data.originalLength;
completedSegments +=1;
workers[i].terminate();
// if all segments are complete, stitch them together
if (completedSegments === NUM_WORKERS) {
const retSummed = sumSegments(processedSegments, originalLength);
packageAndDownload(retSummed);



