Music demixing, song splitting, stem separation: what's the difference?
Posted by sevagh on 24 November 2023
Category: getting-started
Table of contents
- Who defined Music demixing?
- Math/science/engineering: source separation
- Music industry: stems and splitters
- Conclusion
- References
What’s in a name? An analysis of the different names used to refer to the task of separating a mixed song into its isolated stems.
Who defined Music demixing?
I technically coined the term music demixing. OK, that’s a heavy exaggeration. What happened is in 2021, I participated in the Music Demixing AI Challenge 2021, on which a subsequent paper was published after the end of the challenge, describing the challenge and the winning systems.
I participated in the challenge as part of my master’s thesis, whose topic was on the time-frequency uncertainty principle and its role in music demixing.
I needed to write about music demixing in my thesis, and my advisor told me that I needed an academic citation that defined such a term before I could use it. The funny thing is neither the summary paper on MDX 21, nor the participant papers, nor the organizers, provided a formal, citable definition of the term “music demixing.”
At the end of the day, I had to be the one! I included a definition of music demixing in my submission to the challenge:
Music source separation is the task of extracting an estimate of one or more isolated sources or instruments (for example, drums or vocals) from musical audio. The task of music demixing or unmixing considers the case where the musical audio is separated into an estimate of all of its constituent sources that can be summed back to the original mixture.
I would say that the vast majority of my sources and references from the world of digital signal processing, engineering, and software conferences/publications (e.g. DAFx/Digital Audio Effects, ISMIR/Music Information Retrieval, ICASSP/IEEE Acoustic Speech Signal Processing), throughout my papers and thesis use the term music source separation.
In this post, I want to explore the different terms used for this task.
Math/science/engineering: source separation
(parts of this are copied verbatim from my thesis! which you can read in full if you’re curious)
Typical music recordings are mono or stereo mixtures, with multiple sound objects (drums, vocals, etc.) sharing the same track. To manipulate the individual sound objects, the stereo audio mixture needs to be separated into a track for each different sound source, in a process called audio source separation [1].
The paper on the Music Demixing Challenge 2021 [2] provides a summary of why the audio source separation problem has been interesting to researchers:
Audio source separation has been studied extensively for decades as it brings benefits in our daily life, driven by many practical applications, e.g., hearing aids, speech diarization, etc. In particular, music source separation (MSS) attracts professional creators because it allows the remixing or reviving of songs to a level never achieved with conventional approaches such as equalizers. Suppressing vocals in songs can also improve the experience of a karaoke application, where people can enjoy singing together on top of the original song (where the vocals were suppressed), instead of relying on content developed specifically for karaoke applications
Computational source separation has a history of at least 50 years [1], originating from the tasks of computational auditory scene analysis (CASA) and blind source separation (BSS). In CASA, the goal is to computationally extract individual streams from recordings of an acoustic scene [3], based on the definition of ASA (auditory scene analysis) [4]. BSS [5] solves a subproblem of CASA which aims to recover the sources of a “mixture of multiple, statistically independent sources that are received with separate sensors” [3]. The term “blind” refers to there being no prior knowledge of what the sources are, and how they were mixed together. In CASA and BSS, therefore, the mixed audio contains unknown sources combined in unknown ways that must be separated.
By contrast, in music source separation and music demixing, the sources are typically known, or have known characteristics. That is to say, in music source separation, the task is not to separate all of the distinct sources in the mixture, but to extract a predefined set of sources, e.g.: harmonic and percussive sources, or the common four sources defined by the MUSDB18-HQ dataset [6]: vocals, drums, bass, and other. Music demixing can be considered as the reverse of a simple (no effects) mixing process of stems in a recording studio:
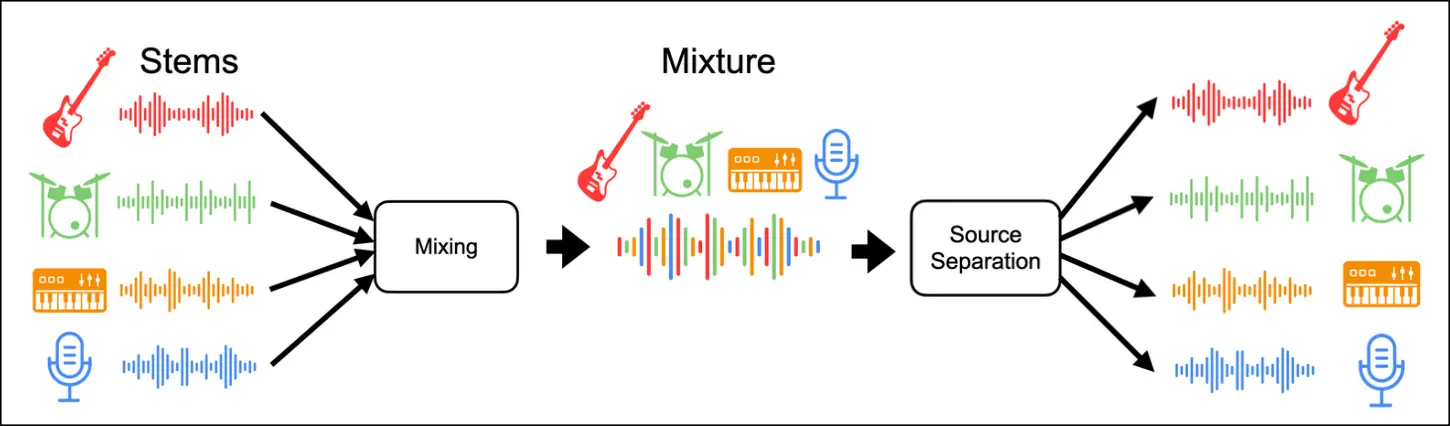
A stem is a grouping of individually recorded instrument tracks that have been combined together in a common category. For example, a drum stem could include all of the tracks of a drum kit (e.g., snare, tom, hihat), and a vocal stem could include all of the vocal tracks from the different singers in the song. Izotope and LANDR, two music tech companies, have written about stems and their history.
In this light we can see that music demixing is simply a combination of multiple music source separation subproblems for all of the desired target stems.
Music industry: stems and splitters
The theoretical underpinnings of modern AI and deep learning techniques were beginning to be discovered by 1960, but the computational power available was too low to take advantage of those ideas (nowadays this is inversed; the insane levels of compute power available in the world have led to huge and powerful AI models like ChatGPT).
Being neither a musician nor a music producer, or audio engineer, I can’t speak with authority on the landscape and history of how people or products have approached stem separation. All I know is that each time I talked about some new algorithm or piece of code I discovered with one of my musician friends, they’d always come back with “oh yeah I have an izotope plugin for that.” Theory and practice are related but not strictly dependent on one another: real-world products can be created before there is a mathematical proof for how they work.
Here’s a nice story of the journey of the HitnMix RipX DAW; they describe how they had been working in the space of commercial music separation offerings since 2001, when I was not yet 10 years old. Another story from Wired discusses the industry and how various academics have over time created startups or products for practical uses in the music industry, such as salvaging or cleaning up old Beatles recordings.
However, when it comes to product offerings, the terminology ends up being different from the academic paper, by necessity since it’s targeted for a different audience. Let’s check some google search results:
- Song splitters: https://vocalremover.org/splitter-ai, https://www.bandlab.com/splitter, https://www.lalal.ai/, https://voice.ai/tools/stem-splitter, https://splitter.ai/, https://songdonkey.ai/, …
- Stem separators: actually the same results as the above
- Music demixers: https://freemusicdemixer.com, https://www.demixer.com/, https://demixor.com/, https://www.audioshake.ai/
- Music instrument isolator: significant overlap with ‘song splitters’, and some more e.g. https://vocalremover.org/, https://moises.ai/, https://www.jamorphosia.com/
These websites and products are all operating in the same space as the academic research papers, with perhaps subtle differences in their outputs. Their customers are different, with papers on music source separation written for fellow academics, and commercial products for stem separation aimed at musicians and music producers.
Commercial offerings and products in the space include LALAL.ai, XTRAX Stems by Audionamix, RX10 by Izotope, Spleeter by Deezer, Moises.ai by Zynaptiq, Stem remover by Wavesfactory, Audioshake.ai, etc. So many choices! What’s your favorite?
Conclusion
This isn’t comprehensive, but it gathers all of the synonyms and terms for music demixing that I’ve encountered over the years in one place. Hope this helps!
References
[1] Rafii, Zafar, Antoine Liutkus, Fabian-Robert Stöter, Stylianos Ioannis Mimilakis, Derry Fitzgerald, and Bryan Pardo. 2018. “An overview of lead and accompaniment separation in music.” IEEE/ACM Transactions on Audio, Speech, and Language Processing; https://arxiv.org/abs/1804.08300
[2] Mitsufuji, Yuki, Giorgio Fabbro, Stefan Uhlich, and Fabian-Robert Stöter. 2021. “Music demixing challenge at ISMIR 2021.” arXiv preprint arXiv:2108.13559; https://arxiv.org/abs/2108.13559
[3] Wang, DeLiang, and Guy J. Brown. 2006. “Fundamentals of computational auditory scene analysis.” In Computational auditory scene analysis: Principles, algorithms, and applications, edited by DeLiang Wang and Guy J. Brown. Wiley-IEEE-Press.
[4] Bregman, Albert S. 1994. Auditory scene analysis: The perceptual organization of sound. MIT Press.
[5] Jutten, Christian, and Jeanny Hérault. 1991. “Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture.” Signal Processing 24 (1): 1–10.
[6] Rafii, Zafar, Antoine Liutkus, Fabian-Robert Stöter, Stylianos Ioannis Mimilakis, and Rachel Bittner. (2017) “The MUSDB18 corpus for music separation”; (2019) “MUSDB18-HQ: an uncompressed version of MUSDB18.”



